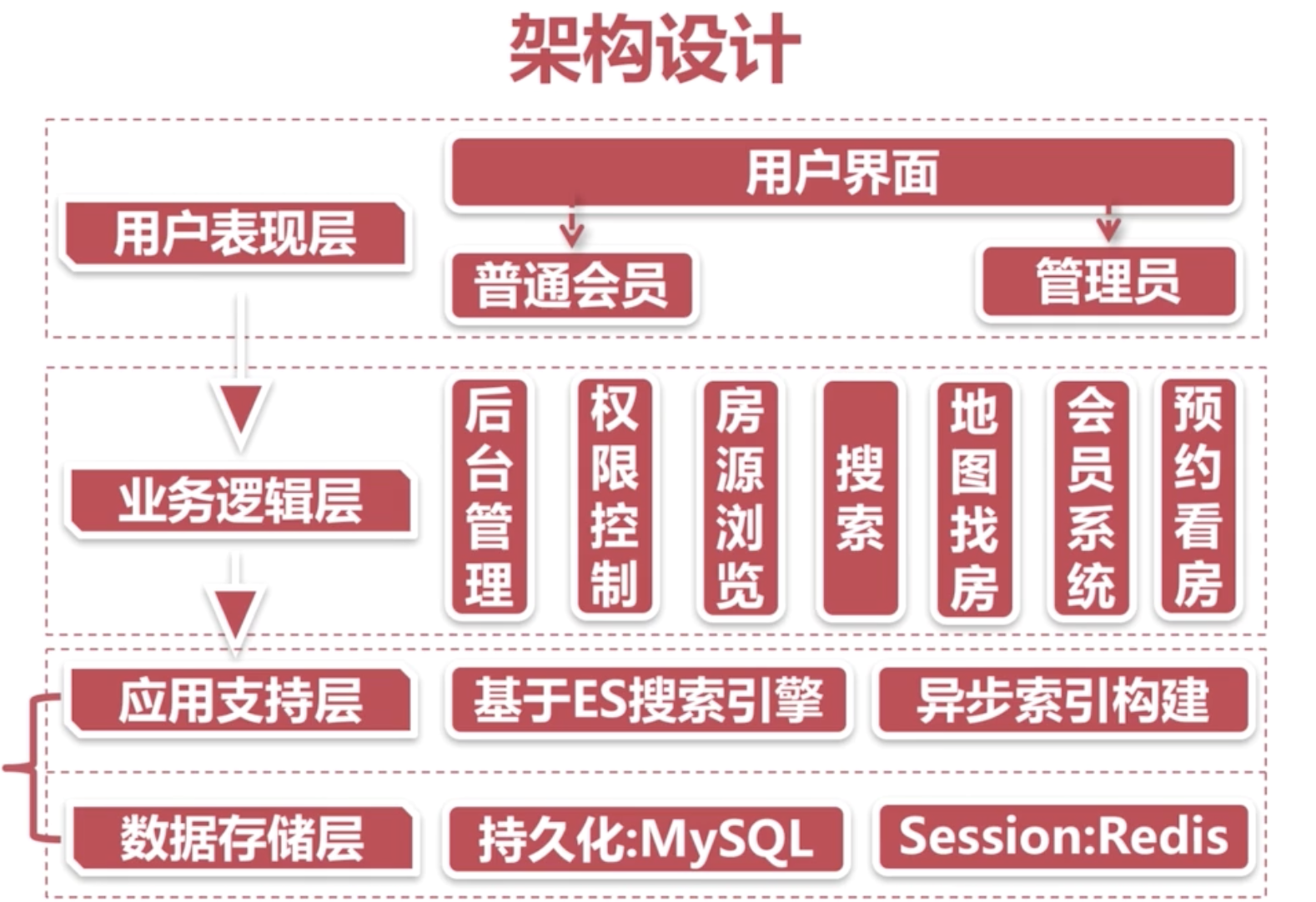
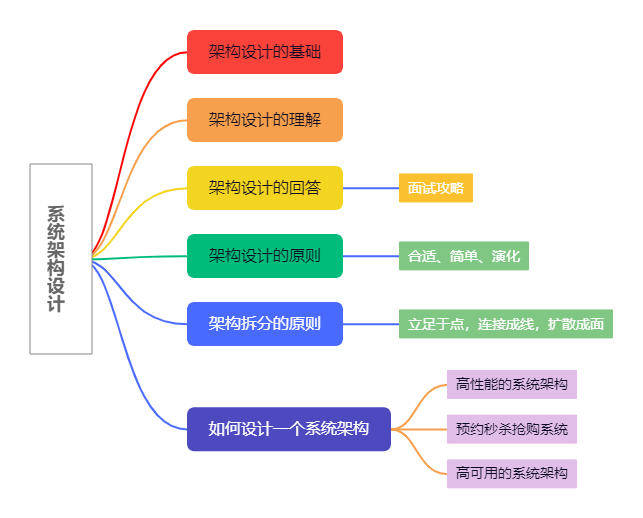
最近梳理了之前学习的架构设计相关的一些课程学习总结,将其整理成了一个大纲脑图,以每篇5分钟系列展现出来,希望对你有所帮助。
高可用,是近年来IT应用系统的常见需求。本篇,我们将聚焦这个话题,了解如何回答此类问题的基本套路。
注意:本篇内容阅读时间可能会超过5分钟,呼呼。
首先,我们需要明确此类问题要回答的重点是如何证明你设计的系统是高可用的,一个基本套路为:
如何评估系统高可用 => 如何监控系统高可用 => 如何保证系统高可用
一个回答示例:
为了确保系统的健康可靠,我设计了一套监控体系,用于在生产环境对系统的可用性进行监控,具体的指标细节可以结合业务场景进行裁剪,比如是游戏领域的话,就很关注流量和客户端连接数。
1、明确系统高可用的评估标准
首先,N个9。即系统可用性指标要求是几个9,大部分互联网公司都要求4个9。
参考架构设计基础部分的一些关键指标
其次,影响请求量占比。即一段时间内(比如1年)的停机影响的请求量占比。

2、设计服务可用性监控系统
首先,假设我们的评估标准是4个9,即99.99%的可用性。
其次,对于一个监控报警体系而言,监控系统主要包括三个类型,我们需要判断需要监控的系统属于哪一类:
(1)基础设施监控报警(比如:服务器主机)
监控报警指标
-
WHY?因为它们是判断系统的基础环境是否为高可用的重要核心指标
-
系统要素:CPU、内存、磁盘
-
网络要素:带宽、网络I/O、CDN、DNS、安全策略 和 负载策略
监控工具
-
Zabbix
-
Prometheus
报警策略
-
三个维度:时间维度、报警级别 和 阈值设置
-
设定报警级别:比如紧急、重要 和 一般
-
设定时间粒度:比如分钟
-
设定对应阈值:比如>=90%为紧急,>=80%为重要,>=70%为一般
-
设定通知方式:短信、钉钉、邮件 等
(2)系统应用监控报警(比如:ASP.NET Core应用,SprintBoot应用等)
监控报警指标
-
服务要素:流量、耗时、错误、心跳、客户端数、连接数
监控工具
-
CAT
-
Zipkin
-
SkyWalking
报警策略
-
和基础设施监控报警策略类似
(3)存储服务监控报警(比如:DB、ElasticSearch、Redis等)
监控报警指标
-
基础要素 和 基础设施指标类似
-
其他要素:集群节点、分片信息、存储数据信息 等有存储指标的监控
监控工具
-
和基础设施监控工具类似
报警策略
-
和基础设施监控报警策略类似
3、设计保证系统高可用措施
在实际场景中,A系统依赖了B系统和C系统,如果B系统或C系统请求处理缓慢,从而让A系统执行查询操作的服务线程阻塞,不能及时释放,直到所有线程资源被沾满,进而无法处理后续的请求。这时,整体服务甚至会发生宕机,这就是服务雪崩现象:即局部故障最终导致了全局故障。
系统高可用性的保障一般是:熔断 和 降级。
(1)首先,我们需要理解 熔断 和 降级 的基本原理。
-
服务熔断
-
理论来源:参考了电路中保险丝的保护原理,当电路出现短路、过载的时候,保险丝就自动熔断,保证整体电路安全;
-
实际场景:服务A调用服务B时,如果服务B返回错误或超时的次数超过一定的阈值,服务A的后续请求将不再调用服务B;
-
本质理解:熔断机制是一个有限状态机,实现的关键是三种状态之间的转换过程;
-
图示:

-
降级处理
-
实际场景:当资源和访问量出现矛盾时,在有限的资源下,放弃部分非核心功能或者服务,保证整体的可用性。
-
本质理解:从架构设计的角度出发,降级设计就是在做取舍,它是一种有损的系统容错方式。
(2)其次,我们需要说明如何实现的熔断 和 降级。
-
熔断实现
-
关闭 转 打开:如果失败次数超过阈值,则断路器打开;
-
打开 转 半打开:如果已熔断,设置一个定时器定期检测服务可用性,倒计时结束就设置为半打开;
-
半打开 转 关闭:如果已半打开,则判断成功次数是否已超过阈值,超过则设置为关闭。
-
降级实现
-
功能降级
-
设计原则:产品功能上的取舍
-
实现方式:通过降级开关控制某个产品功能的可用或不可用,比如将其设置在Apollo中,在高并发场景下,手动或自动开启开关,实现功能降级。
-
读操作降级
-
设计原则:取舍非核心服务
-
实现方式:提前设计 数据兜底 服务:比如 兜底数据提前存储在缓存中,降级时从缓存中读取兜底数据;此外,还可以做多级缓存,即Nginx Cache => Redis Cache => Application Cache 的思路,最后通过DB做兜底。
-
写操作降级
-
设计原则:取舍系统一致性,即将强一致性 转换成 最终一致性
-
实现方式:比如将直接同步调用写DB的操作 降级为 先写缓存再异步写入DB,又比如 将同步RPC服务调用 降级为 先发到MQ消息队列再由消费服务端异步处理。
(3)最后,系统故障是不可避免的。
做架构设计的时候就需要把故障当作不可或缺的一环来处理,因此在分布式系统设计和开发的过程中,要通过各种架构手段来提高系统可用性。
4、补充参考:线上故障处理原则
对于线上故障,要有应急响应机制,一般互联网公司都有如下所示的故障处理原则。

总体来说,任何线上故障的首要原则都是应在第一时间恢复服务,然后再进行故障的定位、分析 和 解决,最后再进行复盘总结经验教训,避免再次发生。
参考资料
李运华,《从0开始学架构》
刘海丰,《架构设计面试精讲》
潘新宇,《23讲搞定后台架构实战》