RegExp
正则表达式 ,一般被创建出来就是用于 字符串的替换 查找方法中的
1.创建正则表达式
var reg = /pattern/flag; // 字面量
var reg = new RegExp("pattern","flags");//构造函数
2.匹配模式
g global 全局匹配
i case-insensitive 不区分大小写
m multiline 多行模式
3.元字符
() [] {} \ / | ^ $ * + .
元字符需要用 转义字符 \ 来转换
4.匹配规则
| . | 匹配除了 /n 和 /r 剩下的全部字符 |
| \n | 匹配字符换行(\r回车,\t制表符,\f换页) |
| \d | 所有数字 |
| \D | 所有非数字 |
| \s | 所有空白符 |
| \S | 所有非空白符 |
| \b | 匹配所有单词边界 |
| \B | 匹配所有非单词边界 |
| \w | 匹配单词 |
| \W | 匹配非单词 |
| [abc] | 匹配方括号内的内容 |
| [^abc] | 匹配非括号内的内容 |
| [a-z] | 匹配a到z 26个字母 -标识范围 |
5.量词
| ? | 匹配0次或这1次(又或者没有) |
| * | 匹配0次或多次 |
| + | 匹配1次或多次 |
| {n} | 匹配n个 |
| {n,} | 匹配至少n个 |
| {n,m} | 匹配至少n次 不超过m次. |
在变量内 ^ 和 $ 分别代表 开头和结束
6.字符串中用到正则的方法 str.function(reg)
var str = '123abc'; var reg = /[a-z]+/g; //匹配多个字母
search 方法 查找匹配内容的起始位置
str.search(reg); //返回3 从第4位开始
replace 方法 替换匹配的内容
str.replace(reg,'你好');//返回 ‘123你好’
replace 结合正则表达式
var str = '123,abc'; var reg = /(\d{3}),([a-z]{3})/g; str.replace(reg,'$2@$1')// 'abc@123' $1和$2分别代表第一个()和第二个()匹配出的内容
//$1 $2 写在字符串里面
var str = '123-abcd'; var reg = /(\d{3})-([a-z]{4})/g; var data = str.replace(reg,function($1,$2,$3){ return $2+"+"+$3;//'123+abcd' })//这里传函数的时候 第一个形参 是原字符串 第二个参数是第一组第三个参数是第二组
正则表达式里面 小括号() 括起来的部分就是一个分组 分别是 $1,$2,$3....
经过一段时间上的使用,后来发现 就上面这些在实际应用中还是不够的,就去看了看全威的网站
补充一些内容
几个重要元字符
? 将?跟在其他限定符(*,+,?,{n},{n,},{n,m})后面 ,将匹配模式变成非贪婪模式
就是只匹配能匹配的最少的内容 如 {n,}? 就只匹配n个
(pattern) 这就是分组匹配,把每个被括号里的正则匹配出来的内容,当做一个组,存在Matches
集合中,js可以配合 replace使用 $1,$2....分别代表各个组匹配出的内容,
用法就在上面replace
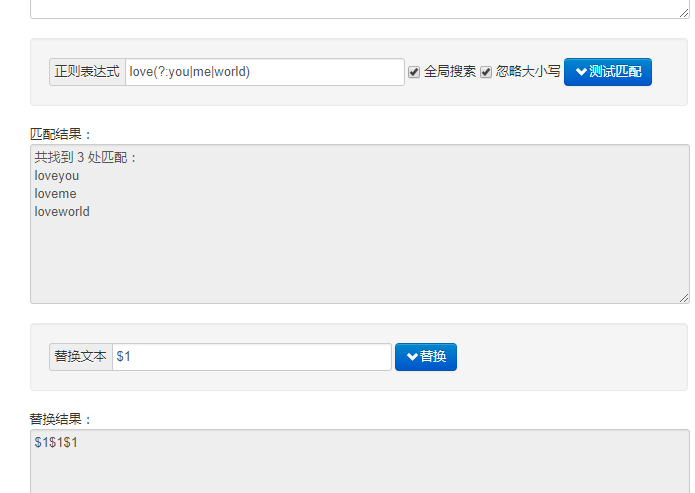
(?:pattern) 匹配patttern的内容,但是不会作为分组使用,即不会被存在Matches集合中
配合 | 可以实现更简易的 或操作
str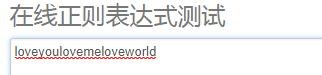
不使用 ?: 进行匹配

匹配结果
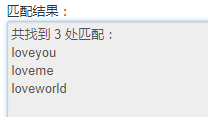
replace替换 (从这里看出 分组存在)
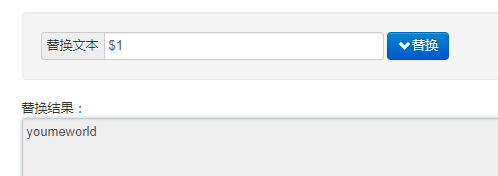
当更改 正则表达式 使用 ?: 可以发现匹配出的结果都是相同的,不同的是在替换的时候$1并不存在,这里把$1当成字符串了
(?=pattern) 正向肯定预查(look ahead positive assert)[预览,积极的断言]
在任何匹配pattern的字符串开始处,匹配查找字符串,这是一个非获取匹配
预查不消耗字符串
(?!pattern) 正向否定预查(negative assert)[消极的 断言]
在任何匹配的pattern 的字符串开始处匹配字符串,同样是一个非捕获匹配
同样预查不消耗字符串

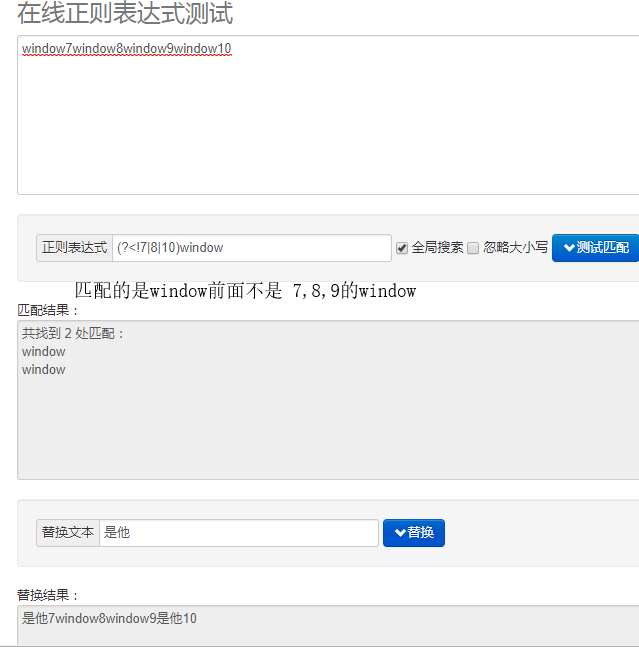
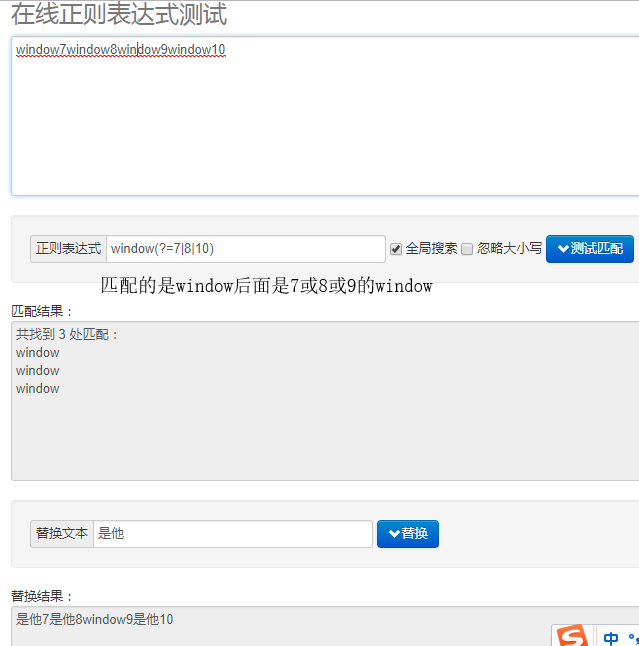
var reg = /window(?=7|8|10)/g; //可以匹配出 window7/window8/window10 中的window 但是不能匹配出window9中的window
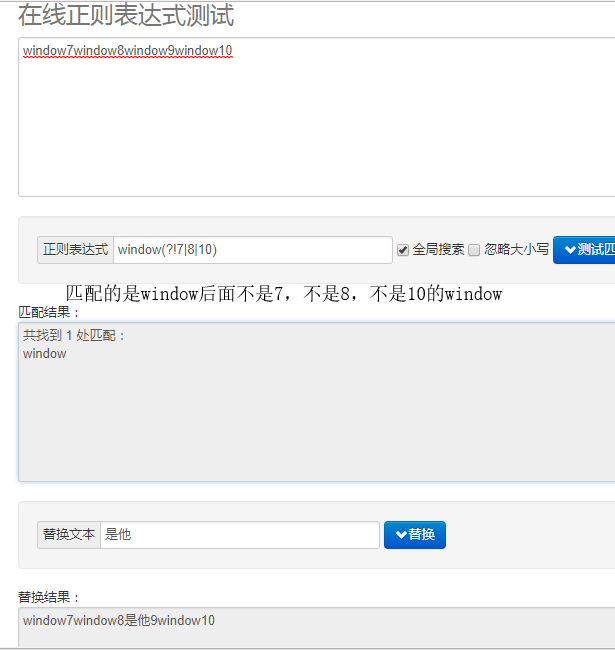
var reg = /window(?!7|8|10)/g; //就不能匹配出 window7/window8/window10 能匹配出除了 window9等等等
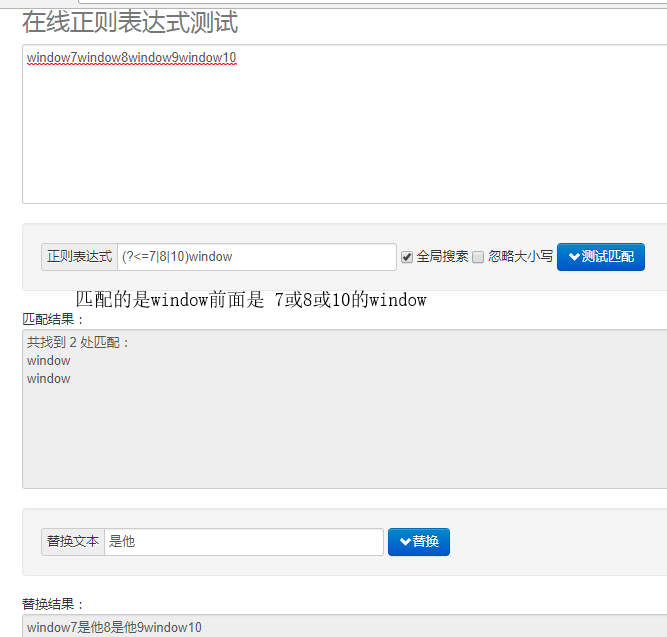
(?<=pattern) 反向肯定预查 与正向的功能基本相同,就是换了预查的方向 查看前面
仍然是预查,不消耗字符串
(?<!pattern) 反向否定预查 同样预查不消耗字符串,