最近在看vue源码的时候发现一个令人头疼的问题,就是正则表达式,在此之前我对正则只有一知半解,没有深入了解,所以看到正则高级写法都不知是什么含义,哎...,所以就去查看相关资料和博主写的,特意整理记录一下学习的过程并用通俗易懂的文章分享给大家,好了,废话不多说,进去正题。
第一章 正则表达式字符匹配
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话。然而关于正则如何匹配字符的学习,大部分人都觉得这块比较杂乱。毕竟元字符太多了,看起来没有系统性,不好记。本章就解决这个问题。
内容包括:
- 两种模糊匹配
- 字符组
- 量词
- 分支结构
1 两种模糊匹配
如果正则只有精确匹配是没多大意义的,比如/hello/,也只能匹配字符串中的"hello"这个子串。
var regex = /hello/;
console.log( regex.test("hello") );
// => true
正则表达式之所以强大,是因为其能实现模糊匹配。而模糊匹配,有两个方向上的“模糊”:横向模糊和纵向模糊。
- 1.1 横向模糊匹配
横向模糊指的是,一个正则可匹配的字符串的长度不是固定的,可以是多种情况的。其实现的方式是使用量词。譬如{m,n},表示连续出现最少m次,最多n次。
比如/ab{2,5}c/表示匹配这样一个字符串:第一个字符是“a”,接下来是2到5个字符“b”,最后是字符“c”。测试如下:
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) );
// => ["abbc", "abbbc", "abbbbc", "abbbbbc"]
//注意:案例中用的正则是/ab{2,5}c/g,后面多了g,它是正则的一个修饰符。表示全局匹配,
//即在目标字符串中按顺序找到满足匹配模式的所有子串,强调的是“所有”,而不只是“第一个”。g是单词global的首字母。
- 1.2 纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。其实现的方式是使用字符组。譬如[abc],表示该字符是可以字符“a”、“b”、“c”中的任何一个。比如/a[123]b/可以匹配如下三种字符串:"a1b"、"a2b"、"a3b"。测试如下:
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) );
// => ["a1b", "a2b", "a3b"]
2. 字符组
需要强调的是,虽叫字符组(字符类),但只是其中一个字符。例如[abc],表示匹配一个字符,它可以是“a”、“b”、“c”之一。
- 2.1 范围表示法
如果字符组里的字符特别多的话,怎么办?
可以使用范围表示法。比如[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。用连字符-来省略和简写。
因为连字符有特殊用途,那么要匹配“a”、“-”、“z”这三者中任意一个字符,该怎么做呢?不能写成[a-z],因为其表示小写字符中的任何一个字符。
可以写成如下的方式:[-az]或[az-]或[a\-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
- 2.2 排除字符组
纵向模糊匹配,还有一种情形就是,某位字符可以是任何东西,但就不能是"a"、"b"、"c"。
此时就是排除字符组(反义字符组)的概念。例如[^abc],表示是一个除"a"、"b"、"c"之外的任意一个字符。字符组的第一位放^(脱字符),表示求反的概念。
当然,也有相应的范围表示法。
- 2.3 常见的简写形式
有了字符组的概念后,一些常见的符号我们也就理解了。因为它们都是系统自带的简写形式。
\d就是[0-9]。表示是一位数字。记忆方式:其英文是digit(数字)。
\D就是[^0-9]。表示除数字外的任意字符。
\w就是[0-9a-zA-Z_]。表示数字、大小写字母和下划线。记忆方式:w是word的简写,也称单词字符。
\W是[^0-9a-zA-Z_]。非单词字符。
\s是[ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。记忆方式:s是space character的首字母。
\S是[^ \t\v\n\r\f]。 非空白符。
.就是[^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。
记忆方式:想想省略号...中的每个点,都可以理解成占位符,表示任何类似的东西。
如果要匹配任意字符怎么办?可以使用[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。
3. 量词
量词也称重复。掌握{m,n}的准确含义后,只需要记住一些简写形式。
- 3.1 简写形式
{m,} 表示至少出现m次。
{m} 等价于{m,m},表示出现m次。
? 等价于{0,1},表示出现或者不出现。记忆方式:问号的意思表示,有吗?
+ 等价于{1,},表示出现至少一次。记忆方式:加号是追加的意思,得先有一个,然后才考虑追加。
* 等价于{0,},表示出现任意次,有可能不出现。记忆方式:看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来。
- 3.2 贪婪匹配和惰性匹配
看如下的例子:
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]
其中正则/\d{2,5}/,表示数字连续出现2到5次。会匹配2位、3位、4位、5位连续数字。
但是其是贪婪的,它会尽可能多的匹配。你能给我6个,我就要5个。你能给我3个,我就3要个。反正只要在能力范围内,越多越好。
我们知道有时贪婪不是一件好事(请看文章最后一个例子)。而惰性匹配,就是尽可能少的匹配:
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["12", "12", "34", "12", "34", "12", "34", "56"]
其中/\d{2,5}?/表示,虽然2到5次都行,当2个就够的时候,就不在往下尝试了。
通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下:
{m,n}?
{m,}?
??
+?
*?
4. 多选分支
一个模式可以实现横向和纵向模糊匹配。而多选分支可以支持多个子模式任选其一。具体形式如下:(p1|p2|p3),其中p1、p2和p3是子模式,用|(管道符)分隔,表示其中任何之一。
例如要匹配"good"和"nice"可以使用/good|nice/。测试如下:
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]
但有个事实我们应该注意,比如我用/good|goodbye/,去匹配"goodbye"字符串时,结果是"good":
var regex = /good|goodbye/g;
var string = "goodbye";
console.log( string.match(regex) );
// => ["good"]
也就是说,分支结构也是惰性的,即当前面的匹配上了,后面的就不再尝试了。‘
第一章小结
掌握字符组和量词就能解决大部分常见的情形,也就是说,当你会了这二者,JS正则算是入门了。
第二章 正则表达式位置匹配
大部分人学习正则时,对于匹配位置的重视程度没有那么高。本章讲讲正则匹配位置的东西。
内容包括:
- 什么是位置?
- 如何匹配位置?
- 位置的特性
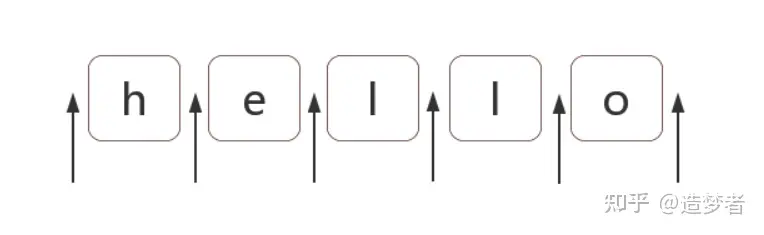
1. 什么是位置呢?
位置是相邻字符之间的位置。比如,下图中箭头所指的地方:
2. 如何匹配位置呢?
在ES5中,共有6个锚字符:
^$\b\B(?=p)(?!p)- 2.1 ^和$
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用"#"替换(位置可以替换成字符的!):
var result = "hello".replace(/^|$/g, '#');
console.log(result);
// => "#hello#"
多行匹配模式时,二者是行的概念,这个需要我们的注意:
var result = "I\nlove\njavascript".replace(/^|$/gm, '#');//解释:每行的开头和结束需要添加#
console.log(result);
/*
#I#
#love#
#javascript#
*/
- 2.2 \b和\B
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置。
比如一个文件名是"[JS] Lesson_01.mp4"中的\b,如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result);
// => "[#JS#] #Lesson_01#.#mp4#"
为什么是这样呢?这需要仔细看看。
首先,我们知道,\w是字符组[0-9a-zA-Z_]的简写形式,即\w是字母数字或者下划线的中任何一个字符。而\W是排除字符组[^0-9a-zA-Z_]的简写形式,即\W是\w以外的任何一个字符。
此时我们可以看看"[#JS#] #Lesson_01#.#mp4#"中的每一个"#",是怎么来的。
- 第一个"#",两边是"["与"J",是\W和\w之间的位置。
- 第二个"#",两边是"S"与"]",也就是\w和\W之间的位置。
- 第三个"#",两边是空格与"L",也就是\W和\w之间的位置。
- 第四个"#",两边是"1"与".",也就是\w和\W之间的位置。
- 第五个"#",两边是"."与"m",也就是\W和\w之间的位置。
- 第六个"#",其对应的位置是结尾,但其前面的字符"4"是\w,即\w和$之间的位置。
知道了\b的概念后,那么\B也就相对好理解了。\B就是\b的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。具体说来就是\w与\w、\W与\W、^与\W,\W与$之间的位置。
比如上面的例子,把所有\B替换成"#":
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#');
console.log(result);
// => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
- 2.3 (?=p)和(?!p)
(?=p),其中p是一个子模式,即p前面的位置。
比如(?=l),表示'l'字符前面的位置,例如:
var result = "hello".replace(/(?=l)/g, '#');
console.log(result);
// => "he#l#lo"
而(?!p)就是(?=p)的反面意思,比如:
var result = "hello".replace(/(?!l)/g, '#');
console.log(result);
// => "#h#ell#o#"
3. 位置的特性
对于位置的理解,我们可以理解成空字符""。
比如"hello"字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";
//也等价于:
var result = /(?=he)^^he(?=\w)llo$\b\b$/.test("hello");
console.log(result);
// => true
第三章 正则表达式括号的作用
括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。
引用某个分组,会有两种情形:1.在JavaScript里引用它,2.在正则表达式里引用它。
1. 分组和分支结构
1.1 分组
我们知道/a+/匹配连续出现的“a”,而要匹配连续出现的“ab”时,需要使用/(ab)+/。
其中括号是提供分组功能,使量词+作用于“ab”这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
1.2 分支结构
而在多选分支结构(p1|p2)中,此处括号的作用也是不言而喻的,提供了子表达式的所有可能。
比如,要匹配如下的字符串:
//I love JavaScript
//I love Regular Expression
//可以使用正则:
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression"))
// => true
// => true
如果去掉正则中的括号,即/^I love JavaScript|Regular Expression$/,匹配字符串是"I love JavaScript"和"Regular Expression",当然这不是我们想要的。
2. 引用分组
这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。而要使用它带来的好处,必须配合使用实现环境的API。
以日期为例。假设格式是yyyy-mm-dd的,我们可以先写一个简单的正则:
var regex = /\d{4}-\d{2}-\d{2}/;
然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
为什么要使用这个正则呢?
2.1 提取数据
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2021-05-16";
console.log( string.match(regex) );
// => ["2021-05-16", "2021", "05", "16", index: 0, input: "2021-05-16"]
match返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。(注意:如果正则是否有修饰符g,match返回的数组格式是不一样的)。
另外也可以使用正则对象的exec方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2021-05-16";
console.log( regex.exec(string) );
// => ["2021-05-16", "2021", "05", "16", index: 0, input: "2021-05-16"]
同时,也可以使用构造函数的全局属性$1至$9来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2021-05-16";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2021"
console.log(RegExp.$2); // "05"
console.log(RegExp.$3); // "16"
2.2 替换
比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2021-05-16";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "05/16/2021"
其中replace中的,第二个参数里用$1、$2、$3指代相应的分组。等价于如下的形式:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2021-05-16";
var result = string.replace(regex, function() {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "05/16/2021"
3. 反向引用
除了使用相应API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。
比如要写一个正则支持匹配如下三种格式:
2016-06-12
2016/06/12
2016.06.12
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // true
其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
注意里面的\1,表示的引用之前的那个分组(-|\/|\.)。不管它匹配到什么(比如-),\1都匹配那个同样的具体某个字符。
我们知道了\1的含义后,那么\2和\3的概念也就理解了,即分别指代第二个和第三个分组。看到这里,此时,恐怕你会有三个问题。
3.1 括号嵌套怎么办?
以左括号(开括号)为准。比如:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log( regex.test(string) ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
我们可以看看这个正则匹配模式:
第一个字符是数字,比如说1,
第二个字符是数字,比如说2,
第三个字符是数字,比如说3,
- 接下来的是\1,是第一个分组内容,那么看第一个开括号对应的分组是什么,是123,
- 接下来的是\2,找到第2个开括号,对应的分组,匹配的内容是1,
- 接下来的是\3,找到第3个开括号,对应的分组,匹配的内容是23,
- 最后的是\4,找到第3个开括号,对应的分组,匹配的内容是3。
3.2 \10表示什么呢?
另外一个疑问可能是,即\10是表示第10个分组,还是\1和0呢?答案是前者第10个分组
虽然一个正则里出现\10比较罕见。测试如下
var regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/;
var string = "123456789# ######"
console.log( regex.test(string) );
// => true3.3 引用不存在的分组会怎样?
因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配反向引用的字符本身。例如\2,就匹配"\2"。注意"\2"表示对"2"进行了转意。
var regex = /\1\2\3\4\5\6\7\8\9/;
console.log( regex.test("\1\2\3\4\5\6\7\8\9") );
console.log( "\1\2\3\4\5\6\7\8\9".split("") );

打印结果
4. 非捕获分组
之前文中出现的分组,都会捕获它们匹配到的数据,以便后续引用,因此也称他们是捕获型分组。
如果只想要括号最原始的功能,但不会引用它,即,既不在API里引用,也不在正则里反向引用。此时可以使用非捕获分组(?:p),例如本文第一个例子可以修改为:
var regex = /(?:ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
5. 相关案例
5.1 字符串trim方法模拟
trim方法是去掉字符串的开头和结尾的空白符。有两种思路去做。
第一种,匹配到开头和结尾的空白符,然后替换成空字符。如:
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}
console.log( trim(" foobar ") );
// => "foobar"
第二种,匹配整个字符串,然后用引用来提取出相应的数据:
function trim(str) {
return str.replace(/^\s*(.*?)\s*$/g, "$1");
}
console.log( trim(" foobar ") );
// => "foobar"
5.2 将每个单词的首字母转换为大写
//思路是找到每个单词的首字母,当然这里不使用非捕获匹配也是可以的。
function titleize(str) {
return str.toLowerCase().replace(/(?:^|\s)\w/g, function(c) {
return c.toUpperCase();
});
}
console.log( titleize('my name is epeli') );
// => "My Name Is Epeli"
5.3 匹配成对标签
要求匹配:
<title>regular expression</title>
<p>laoyao bye bye</p>
不匹配:
<title>wrong!</p>匹配一个开标签,可以使用正则<[^>]+>,
匹配一个闭标签,可以使用<\/[^>]+>,
但是要求匹配成对标签,那就需要使用反向引用,如:
var regex = /<([^>]+)>[\d\D]*<\/\1>/;
var string1 = "<title>regular expression</title>";
var string2 = "<p>laoyao bye bye</p>";
var string3 = "<title>wrong!</p>";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // false
其中开标签<[^>]+>改成<([^>]+)>,使用括号的目的是为了后面使用反向引用,而提供分组。闭标签使用了反向引用,<\/\1>。
另外[\d\D]的意思是,这个字符是数字或者不是数字,因此,也就是匹配任意字符的意思。