正则:
正则表达式,又称规则表达式。是匹配模式,要么匹配字符,要么匹配位置。
正则表达式的两种创建方式:
// 直接字面量
var reg = /^\d|\d$/gmi;
// 构造函数 new RegExp();
var reg = new RegExp('^\d|\d$', 'gmi');
注意:RegExp 构造函数的两个参数都是字符串;
正则对象的实例属性:
修饰符相关, 返回一个布尔值,表示是否设置了对于的修饰符。
RegExp.prototype.ignoreCase // 表示是否设置了忽略大小 i 修饰符 RegExp.prototype.global // 表示是否设置了全局匹配 g 修饰符 RegExp.prototype.multiline // 表示是否设置了多行匹配 m 修饰符 var reg = /abc/igm; reg.ignoreCase // true reg.global // true reg.multiline // true
其他属性
RegExp.prototype.lastIndex // 返回一个整数, 表示下一次开始搜索的位置。可读可写,搜索时才有用 RegExp.prototype.source //返回正则标的是的字符串形式 var reg = /abc/igm; reg.lastIndex // 0 reg.source // "abc"
正则的实例方法:
RegExp.prototype.test();
用来检查字符串是否匹配某个正则表达式,匹配返回true,否则返回false;
/hello/.test("hello word!"); // true
如果正则表示带有 g 修饰符, 则每次 test 方法都是从上一次结束的位置开始向后匹配。
var reg = /a/g; var str = "_a_a"; console.log( reg.lastIndex ); // 0 reg.test( str ); // true console.log( reg.lastIndex ); // 2 reg.test( str ); // true console.log( reg.lastIndex ); // 4 reg.test( str ); // false
RegExp.prototype.exec();
a. 匹配失败, 返回 null
b. 匹配成功, 返回一个数组, 成员是匹配成功的子字符串
c. 全局匹配时, lastIndex 为累加, 下一次搜索的位置是上一次匹配成功结束的位置
var str = "a-b-c"; /a/.exec(str); // ["a"] /d/.exec(str); // null
利用g修饰符允许多次匹配的特点,可以用一个循环完成全局匹配
var reg = /a/g;
var str = "abc-abc-abc";
while( true ){
var match = reg.exec(str);
if(!match){
break;
}
console.log("#" + match.index + ":" + match[0]);
}
// #0:a
// #4:a
// #8:a
字符串的实例方法:
String.prototype.match()
a. 匹配成功, 返回一个数组, 成员是所有的匹配的子字符串
b. 匹配失败, 返回null
c. 带有g修饰符时, 会一次性返回所有匹配成结果
d. 匹配总是从字符串的第一个字符位置开始
var string = "2017-06-26";
console.log( string.match(/\d+/g) );
// ["2017", "06", "26"]
console.log( string.match(/\d{5}/g) );
// null
String.prototype.search()
a. 返回第一个满足条件的匹配结果在整个字符串的位置 b. 匹配失败, 返回 -1 var str = "abcdefg"; console.log( str.search(/\d/g) ); // -1 console.log( str.search(/d/g) ); // 3 注: 忽略全局匹配g修饰符, 只要匹配上就不再匹配
String.prototype.replace()
按照给定的正则表达式进行替换, 返回替换后的字符串
接受两个参数:
A. 第一个参数是正则表达式, 表示搜索模式
B. 第二个参数是替换的内容, 可以是字符串, 也可以是函数
var str = "aaa";
str.replace("a", "b"); // "baa"
str.replace(/a/, "b"); // "baa"
str.replace(/a/g, "b"); // "bbb" 全局匹配替换
当第二个参数是字符串时, 以下的字符有特殊的含义:
$& : 匹配到的子串文本
$` : 匹配到的子串的左边文本
$' : 匹配到的子串的右边文本
$n : 匹配成功的第n组内容, n 是从1开始的自然数
$$ : 美元符号
例如: 把"2,3,5", 变成"5=2+3"
var str = "2,3,5"; console.log( str.replace(/(\d+),(\d+),(\d+)/, "$3=$1+$2") ); // "5=2+3"
例如: 把"2,3,5", 变成"222,333,555"
var str = "2,3,5"; console.log( str.replace(/(\d+)/g, "$&$&$&") ); // "222,333,555"
例如: 把"2+3=5", 变成"2+3=2+3=5=5"
var str = "2+3=5"; console.log( str.replace(/=/, "$&$`$&$'$&") ); // "2+3=2+3=5=5"
第二个参数是函数时
var str = "1234 2345 3456";
var reg = /(\d)\d{2}(\d)/g
str.replace(reg, function(match, $1, $2, index, input){
// match : 匹配到的内容
// $1\$2 : 捕获到分组中的内容
// index : 匹配到的内容在整个字符串中的位置
// input : 原字符串
console.log([match, $1, $2, index, input]);
});
// ["1234", "1", "4", 0, "1234 2345 3456"]
// ["2345", "2", "5", 5, "1234 2345 3456"]
// ["3456", "3", "6", 10, "1234 2345 3456"]
String.prototype.split()
按照给定规则进行字符串分割, 返回一个数组
例如: 目标字符串是"html,css,javascript", 按逗号来分隔
var str = "html,css,javascript"; console.log( str.split(/,/) ); // ["html", "css", "javascript"]
分隔日期格式
var reg = /\D/; console.log( "2018/09/05".split(reg) ); // ["2018", "09", "05"] console.log( "2018-09-05".split(reg) ); // ["2018", "09", "05"] console.log( "2018.09.05".split(reg) ); // ["2018", "09", "05"]
正则表达式匹配规则:
字符组:
方括号[] 用来查找某个范围内的字符, 是是其中一个字符
[abc] => 表示或者的意思,匹配一个字符,可以是"a"、"b"、"c"之一
[^abc] => ^表示求反,是一个除"a"、"b"、"c"之外的任意一个字符
[0-9] => -是连字符,0到9的数字
[A-z] => 大写A 到 小写z 的字符
纵向模糊匹配:
指的是,一个正则匹配的字符串,具体到某一位字符串时,它可以不是某个确定的字符。
实现的方式是使用字符组。如: [abc], 表示可以是"a"、"b"、"c"中的任何一个。
var reg = /a[123]b/g; var str = "a0b a1b a2b a3b a4b"; console.log( str.match(reg) ); // ["a1b", "a2b", "a3b"]
量词(匹配重复):
{m} => 表示出现 m 次
{m, } => 表示至少出现 m 次
{m, n} => 表示出现 m 次 到 n 次
? => 等价于{0,1}, 0次 或 1次
+ => 等价于{1, }, 1次 或 多次
* => 等价于{0, }, 0次 或 多次
横向模糊匹配:
指的是,一个正则可匹配的字符串的长度是不固定的,可以是多种情况的。
实现的方式是使用量词。如: b{2, 5} 连续出现最少2次,最多5次
例: 正则表达式/ab{2, 5}c/g; 表示匹配这样一个字符串: 第一个字符是"a", 接下来是2到5个"b"字符, 最后一个是"c"字符。
var reg = /ab{2, 5}c/g;
var str = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( str.match(reg) );
// ["abbc", "abbbc", "abbbbc", "abbbbbc"]
多选分支: 也是惰性匹配,即当前匹配上了,就不再往后尝试
(p1|p2|p3),其中p1、p2、p3是子模式,用 | 分隔,表示其中任何一个.
var reg = /good|nice/g; var str = 'good idea, nice try.'; console.log( str.match(reg) ); // ["good", "nice"]
多选分支的惰性匹配
var reg = /goodbye|good/g; var str = "goodbye"; console.log( str.match(reg) ); // ["goodbye"]
贪婪匹配和惰性匹配:
*?、+?、??、{}?
贪婪匹配: 是尽可能的多匹配;
var reg = /\d{2, 5}/g;
var str = "123 1234 12345 123456";
console.log( str.match(reg) );
// ["123", "1234", "12345", "12345"]
注: /\d{2,5}/表示,数字连续出现2到5次,会匹配2位、3位、4位、5位连续数字
惰性匹配:尽可能的少匹配;
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// ["12", "12", "34", "12", "34", "12", "34", "56"]
注: /\d{2,5}?/表示,数字连续出现2到5次都行,当2个就够的时候,就不再往下尝试了。
预定义模式:
// 数字 \d 等价于 [0-9], 表示是一位数字 // 非数字 \D 等价于 [^0-9], 表示除数字外的任意字符 // 数字、字母、下划线 \w 等价于 [0-9a-zA-Z_], 表示数字、字母、下划线, 称单词字符 // 非单词字符 \W 等价于 [^0-9a-zA-Z_], 表示非单词字符 \s 等价于 [ \t\v\n\r\f], 表示空白符 \S 等价于 [^ \t\v\n\r\f], 表示非空白符 . 等价于 [^\n\r\u2028\u2029] 通配符 除换行符、回车符、行分隔符、段分隔符以外 任意字符 匹配任意字符: [\d\D]、[\w\W]、[\s\S]、[^] 中任何一个
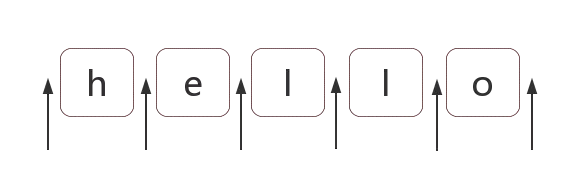
正则表达式位置匹配:
正则的匹配模式, 要么匹配字符, 要么匹配位置。
什么是位置, 如图: (字符与字符之间的位置)
锚字符:
^ => 匹配开头,在多行匹配中匹配行开头
$ => 匹配结尾,在多行匹配中匹配行结尾
匹配开头 和 匹配结尾 var result = 'hello'.replace(/^|$/g, '#'); console.log( result ); // "#hello#" 多行匹配模式时,二者是行的概念 var result = "I\nlove\njavascript".replace(/^|$/gm, '#'); console.log( result ); /* #I# #love# #javascript# */
\b => 单词边界, 是\w和\W之间的位置, 包括\w和^|$之间的位置
\B => 非单词边界, 是\w和\w、\W和\W、^|$和\W之间的位置
单词边界 和 非边界 var result = "[JS] Lesson_01.mp4".replace(/\b/g,'#'); console.log( result ); // "[#JS#] #Lesson_01#.#mp4#"
分解:
\w是字符组[0-9a-zA-Z_] 的简写形式,是数字字母或下划线的任何一个字符。
\W是排除字符组[^0-9a-zA-Z_]的简写形式,是除\w以外的任何一个字符
第一个"#", 两边是"["与"J", 是\W和\w之间的位置
第二个"#", 两边是"S"与"]", 也就是\w和\W之间的位置
第三个"#", 两边是空格与"L", 是\W和\w之间的位置
第四个"#", 两边是"1"与".", 是\w和\W之间的位置
第五个"#", 两边是"."与"m", 是\W和\w之间的位置
第六个"#", 对应的位置是结尾,字符"4"是\w,即\w和$之间的位置
非单词边界的位置:
\B 在字符串中所有位置中,扣掉\b,剩下的都是\B的。
具体说就是\w与\w、\W与\W、^与\W、\W与$之间的位置
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#'); console.log(result); // "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
x(?=y) 称之为先行断言, x只有在y前面才匹配, y不计入结果
var result = "hello word!".replace(/(?=o)/g,'#'); // 左看看 console.log( result ); // 表示是在o字符前面的位置替换"#" // "hell#o w#ord!"
x(?!y) 称之为先行否定断言, x只有不在y前面才匹配。
var result = "hello word!".replace(/(?!o)/g, '#'); console.log( result ); // 表示是在不是o字符前面的位置替换"#" // "#h#e#l#lo# #wo#r#d#!#" '3.14'.match(/\d+(?!\.)/g); // 右看看 // ["14"] 匹配不在小数点前面的数字/ 匹配小数点后面的数字
正则表达式括号的作用:
分组:
/a+/ 匹配连续出现的"a"
/(ab)+/ 匹配连续出现的"ab"
括号提供的是分组的功能,表示的是一个整体。
var reg = /(ab)+/g; var str = "ababa abbb ababab"; console.log( str.match(reg) ); // ["abab", "ab", "ababab"]
分支结构:
在多选分支结构(p1|p2)中,此处括号的作用也是一组,表示子表达式的所有可能。
var reg = /^I love (A | B)$/;
console.log( reg.test("I love A") ); // true
console.log( reg.test("I love B") ); // true
console.log( reg.text("I love c") ); // false
引用分组:
提取数据
var reg = /(\d{4})-(\d{2})-(\d{2})/;
console.log( "2018-09-01".match(reg) );
// ["2018-09-01", "2018", "09", "01", index: 0, input: "2018-09-01"]
match 返回的一个数组,第一个是整体匹配结果,然后是各个分组匹配的内容。
也可以使用正则对象exec方法
var reg = /(\d{4})-(\d{2})-(\d{2})/;
console.log( reg.exec("2018-09-01") );
// ["2018-09-01", "2018", "09", "01", index: 0, input: "2018-09-01"]
分组可以使用构造函数的全局属性 $1 至 $9 来获取
console.log( RegExp.$1 ); // "2018" console.log( RegExp.$2 ); // "09" console.log( RegExp.$3 ); // "01"
替换:
把yyyy-mm-dd格式,替换成 mm/dd/yyyy怎么做?
var reg = /(\d{4})-(\d{2})-(\d{2})/;
"2018-09-01".replace(reg, "$2$3$1");
// "09/01/2018"
其中replace中的, 第二个参数里的 $1、$2、$3指代相应的分组。
等价于:
var reg = /(\d{4})-(\d{2})-(\d{2})/;
"2018-09-01".replace(reg, function(){
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
// "09/01/2018"
也等价于:
var reg = /(\d{4})-(\d{2})-(\d{2})/;
"2018-09-01".replace(reg, function(match, year, month, day){
return month + "/" + day + "/" + year;
});
// "09/01/2018"
反向引用: 在正则本身里引用分组,只能引用之前出现的分组,即反向引用。
匹配如下三种日期格式:
2018-09-01、2018/09/01、2018.09.01
var reg = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
console.log( reg.test("2018-09-01") ); // true
console.log( reg.test("2018/09/01") ); // true
console.log( reg.test("2018.09.01") ); // true
console.log( reg.test("2018/09-01") ); // true
反向引用\1, 表示的引用之前那个分组(-|\/|\.) 指代的是第一个分组
var reg = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
console.log( reg.test("2018-09-01") ); // true
console.log( reg.test("2018/09/01") ); // true
console.log( reg.test("2018.09.01") ); // true
console.log( reg.test("2018/09-01") ); // true
括号嵌套: 以左括号(开括号) 为准。
var reg = /^((\d)(\d(\d)))\1\2\3\4$/;
console.log( reg.test('1231231233') ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
非捕获分组: 不能被引用
var reg = /(?:ab)+/g; console.log( "ababa abbb ababab".match(reg) ); // ["abab", "ab", "ababab"]
正则表达式操作符的优先级
1. 转义符 \
2. 括号和方括号 (...)、(?:...)、(?=...)、(?!...)、[...]
3. 量词限定符 {...}、?、*、+
4. 位置和序列 ^、$、\元字符、一般字符
5. 管道符 (| 或)
操作符的优先级从上往下,由高到低
分析:
/ab?(c|de*)+|fg/ - 由于括号的存在,所有,(c|de*) 是一个整体结构 - 在(c|de*)中,注意其中的量词 *, 因此e*是一个整体结构 - 因为分支结构"|"优先级最低,因此c是一个整体,de*是另一个整体 - 同理,整个正则分成了a、b?、(...)+、f、g, 由于分支的原因,又可以分成 ab?(c|de*)+ 和 fg这两部分
元字符转义问题:
所谓元字符,就是正则中有特殊含义的字符;
^ $ . * + ? | \ / ( ) [ ] { } = ! : - ,
var str = "^$.*+?|\\/[]{}=!:-,"; // 字符串中的\字符需要转义的
var reg = /\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,/;
console.log( reg.test(str) ); // true
字符组中的元字符
跟字符组相关的元字符有[]、^、-, 因此在会引起歧义的地方进行转义。
例如开头的^必须转义,不然会把整个字符组,看成反义字符组。
var str = "^$.*+?|\\/[]{}=!:-,";
var reg = /[\^$.*+?|\\/\[\]{}=!:\-,]/g;
console.log( str.match(reg) );
// ["^", "$", ".", "*", "+", "?", "|", "\", "/",
"[", "]", "{", "}", "=", "!", ":", "-", ","]
匹配"[abc]"和""
由于[abc]是一个字符组,要匹配字符串"[abc]"时,我们需要把正则中的元字符先进行转义如:/\[abc\]/ 或 /\[abc]/ 第一个方括号转义之后,后面的方括号构不成字符组,就不会引发歧义了。
var str = "[abc]"; var reg = /\[abc]/g; cosnole.log( str.match(reg)[0] ); // "[abc]"
= ! : - , 等符号,只要不在特殊结构中,也不需要转义。
括号需要前后都转义 /\(123\)/
^ $ . * + ? | \ /等字符,只要不在字符组内,都需要转义
正则表达式的运行步骤:
1. 编译
2. 设定起始位置
3. 尝试匹配
4. 匹配失败的话, 从下一位开始继续第3步
5. 最终结果: 匹配成功或失败
A. 使用具体型字符组来代替通配符,来消除回溯
B. 使用非捕获分组
因为括号的作用之一是,捕获分组和分支里的数据, 保存到内存中
当我们不需要使用分组引用和反向引用时, 可以使用非捕获分组
/^[+-]?(\d+\.\d+|\.\d+)$/
修改成
/^[+-]?(?:\d+\.\d+|\.\d+)$/
C. 独立出确定字符
如: /a++/ => /aa*/
D. 提取分支公共部分
如: /^abc|^def/ => /^(?:abc|def)/
/this|that/ => /th(?:is|at)/
E. 减少分支的数量,减少它们的范围
如: /red|read/ => /rea?d/
正则表达式案例:
function getElementsByClassName(className){
// 获取页面中所有的标签元素
var elements = document.getElementsByTagName('*');
var reg = new RegExp("(^|\\s)" + className + "(\\s|$)");
var result = [];
for (var i = 0; i < elements.length; i++){
var element = elements[i];
if( reg.test(element.className)){
result.push(element);
}
}
return result;
}
console.log( getElementsByClassName('item') );
// [a.item, div.item, p.item, ...]
// 实现字符串的 trim 函数,去除字符串两边的空格。
String.prototype.trim = function () {
// 方式一:将匹配到的每一个结果都用''替换
return this.replace(/(^\s+)|(\s+$)/g, function(){
return '';
});
// 方式二:和方式一的原理相同
return this.replace(/(^\s+)|(\s+$)/g, '');
// 方式三: 匹配整个字符串, 用引用来提取相应的数据
return this.replace(/^\s*(.*?)\s*$/g, "$1");
};
" Miss You! ".trim();
// "Miss You!"
// 把"http://www.baidu.com/?name=yuix&id=123456"
// 生成 {"name": "yuxi", "id": 123456}
function getUrlParamsObj(){
var obj = {};
// 获取URL的参数部分
var params = window.location.search.substr(1);
// [^&=]+ 表是不含&或=的连续字符, 加上() 就是提取对应字符串
var reg = /([^&=]+)=([^&=]*)/gi;
params.replace(reg, function(rs, $1, $2){
obj[$1] = decodeURIComponent($2);
});
return obj;
}
function getDataType(obj) {
var str = Object.prototype.toString.call(obj);
var reg = /\[object\s(\w+)\]/;
str = str.replace(reg, '$1'); // [object Xxx]
return str.toLowerCase();
// number、string、array、object、null、undefined、boolean
}
getDataType(1); // "number"
getDataType("1"); // "string"
getDataType([]); // "array"
getDataType({}); // "object"
getDataType(null); // "null"
getDataType(undefined); // "undefined"
getDataType(false); // "boolean"
String.prototype.insetAt = function(str, offset){
offset = offset + 1;
// 使用RegExp()构造函数创建正则表达式
var reg = new RegExp("(^.{"+offset+"})"); // /^.{3}/
return this.replace(reg, '$1' + str);
}
"abcd".insetAt('2018', 2); // 在第二个字符后面插入2018
// "abc2018d"
function formatTel(tel){
tel += '';
var reg = /(\d{3})(\d{4})(\d{4})/;
// 方式一
return tel.replace(reg, function(rs, $1, $2, $3){
return $1 + '****' + $3;
});
// 方式二
return tel.replace(reg, "$1****$3");
}
formatTel("13551209931");
// "135****9931"