正则表达式(英语:Regular Expression),描述了一种字符串匹配的模式(pattern)、规则。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
- 可以通过正则表达式,从字符串中获取我们想要的特定部分
正则图形化工具:
创建方式
-
字面量法
const reg = /\d/g; // g表示全局匹配。不加表示搜索到第一个停止。 -
构造函数法
- 字符串 + 修饰符:
const reg= new RegExp('abc', 'g'); // 注意有两个反斜线转义 - 正则表达式:
const reg = new RegExp(/abc/g); - 正则表达式+修饰符:
const reg = new RegExp(/abc/g, 'i'); // 等价于/abc/i,第二个参数中的修饰符会覆盖第一个参数中的修饰符
- 字符串 + 修饰符:
普通字符
普通字符,包括没有显式指定为元字符的所有可打印和不可打印字符(这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号),通常正则表达式里面使用的就是数字、英文字母、部分标点符号。
元字符
元字符,又被称为特殊字符,是一些在正则表达式中约定用来表示特殊语义的字符。
预定义类
| 字符 | 等价类 | 含义 |
|---|---|---|
| . | [^\r\n] | 除换行回车外的任意字符 |
| \d | [0-9] | 任意数字字符 |
| \D | [^0-9] | 非数字字符 |
| \s | [\r\n\t\x0B\f] | 空白符 |
| \S | [^\r\n\t\x0B\f] | 非空白符 |
| \w | [a-zA-Z_0-9] | 单词字符(字母数字下划线共63个字符) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
| \b | 单词边界 | |
| \B | 非单词边界 |
量词,实现多个相同字符的匹配
| 字符 | 含义 |
|---|---|
| ? | 0 | 1(至多出现一次) |
| + | >= 1(至少出现一次) |
| ***** | >= 0(任意次) |
| {n} | 出现n次 |
| {n,m} | 出现n-m次 |
| {n,} | 至少出现n次 |
| {0, n} | 至多出现n次 |
位置边界
-
单词边界
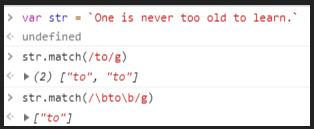
\b单词是构成句子和文章的基本单位,一个常见的使用场景是把文章或句子中的特定单词找出来。如:
One is never too old to learn.我想找到
to这个单词,但是如果只是使用/to/这个正则,就会同时匹配到cat和too这两处文本。这时候我们就需要使用边界#则表达式\b,其中b是boundary的首字母,改写成/\bto\b/,这样就只会匹配到to这个单词。
- 字符串边界
^字符串开头$字符串结尾
其它元字符
|:或。比如/abc|def/ 配abc或def
^:但是在[]内是取反.如[^abc]表示匹配的是除了a、b、c以外的内容。
\:转义
():分组
[]:匹配括号中的一类字符,比如[abc]则可以匹配a或b或c。也可以使用[a-z]来连接两个字符表示从a到z的任意字符,这是闭区间,所以包括a和z,[]中也可以连写。如[a-zA-Z]表示匹配所有大小写字母。
修饰符
| 修饰符 | 含义 |
|---|---|
| g | global 全局搜索,默认是匹配到第一个就停止 |
| i | ignore case 忽略大小写,默认大小写敏感 |
| m | multiline 多行搜索。默认是单行搜索。 |
| u | unicode 用来处理4字节的UTF-16编码字符。(ES 6新增) |
| y | sticky 与g类似,也是全局匹配。但y确保匹配必须从剩余的第一个位置开始。(ES 6新增) |
| s | 开启dotAll, 解决/./无法匹配\n\r等分隔符(ES 9新增) |
举个栗子:
- m
const aaa = `@123
@234
@345`;
aaa.replace(/^@\d/gm,'Q'); // 如果不加m则只有"@1"会被替换
- u
ES 6的字符串扩展中新增了使用大括号表示 Unicode 字符,如果使用这种表示法,那么在正则表达式中必须加上u修饰符,才能识别其中的大括号,否则{}会被解读为量词:
/\u{61}/.test('a'); // false,表示必须要匹配61个u字符
/\u{61}/u.test('a'); // true
/\u{20BB7}/u.test(''); // true
- y
y与g一样都是全局匹配,但g只要剩余串中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始匹配,这也就是“粘连(sticky)”的涵义:
var s = 'aaa_aa_a';
var r1 = /a+/g;
var r2 = /a+/y;
s.replace(r1, 'X'); // "X_X_X"
s.replace(r2, 'X'); //"X_aa_a"
如何检测正则表达式使用了u或y修饰符呢?
ES 6新增了unicode和sticky属性分别来检测:
var r2 = /\u{61}/u;
r2.unicode; // true
var r = /a+/y;
r.sticky; // true
另外ES 6还新增了flags属性用来查看正则表达式使用了哪些修饰符:
var r2 = /\u{61}/ugimy;
r2.flags; // "gimuy"
- s
// dot www.imooc.com dotAll
const reg = /./
console.log(reg.test('5')) // true
console.log(reg.test('x')) // true
console.log(reg.test('\n')) // false
console.log(reg.test('\r')) // false
console.log(reg.test('\u{2028}')) // false
console.log(reg.test('\u{2029}')) // false
const reg = /./s
console.log(reg.test('5')) // true
console.log(reg.test('x')) // true
console.log(reg.test('\n')) // true
console.log(reg.test('\r')) // true
console.log(reg.test('\u{2028}')) // true
console.log(reg.test('\u{2029}')) // true
贪婪模式与非贪婪模式
-
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。
-
从正则语法的角度来讲,被匹配优先量词修饰的子表达式使用的就是贪婪模式,如"(Expression)+";被忽略优先量词修饰的子表达式使用的就是非贪婪模式,如"(Expression)+?"。
-
属于贪婪模式的量词,也叫做匹配优先量词
- 包括:"{m,n}"、"{m,}"、"?"、"*"、"+"
- 非贪婪模式用法:"{m,n}?"、"{m,}?"、"??"、"*?"、"+?"
-
案例:
// 思考下:`'12345678'.replace(/\d{3,6}/g, 'y');` // 结果是`yy78`还是`y78`呢? // 我们在浏览器控制台打印出是`y78`,所以**正则表达式是贪婪**的,它会尽可能多的去匹配! // 那想让它尽可能少的匹配(非贪婪)咋办,很简单--在**量词**后面加**?**就可以了: '12345678'.replace(/\d{3,6}?/g, 'y'); // yy78 // 非贪婪模式 '12345678'.replace(/\d{3,6}/g, 'y'); // y78
前瞻与后顾
前瞻分正向和反向,同样的后顾也分正向和反向。
| 名称 | 表示 | 含义 |
|---|---|---|
| 正向前瞻(先行断言) | exp(?=assert) | 匹配exp正则且满足assert条件的 |
| 反向前瞻(先行否定断言) | exp(?!assert) | 匹配exp正则且不满足assert条件的 |
| 正向后顾(后行断言) | exp(?<=assert) | es9 新增 |
| 反向后顾(后行否定断言) | exp(?<!assert) | es9 新增 |
-
正向前瞻:x只有在y前面才匹配,写成/x(?=y)/
- 只匹配在数字之前的单词:
'a2*34*()va23'.replace(/\w(?=\d)/g,'X')// "X2*X4*()vXX3"
-
反向前瞻:x只有不在y前面才匹配,写成/x(?!y)/
- 只匹配不在数字之前的单词:
'a2*34*()va23'.replace(/\w(?!\d)/g,'X') // "aX*3X*()Xa2X"
-
正向后顾
-
const str = 'ecmascript' const result = str.match(/(?<=ecma)script/) // ["script", index: 4, input: "ecmascript", groups: undefined]
-
-
反向后顾
-
const str = 'ecmascript' const result = str.match(/(?<!ecma)script/) // null
-
分组
-
重复单个字符,非常简单,直接在字符后卖弄加上限定符即可。
- a+ 表示匹配1个或一个以上的a,a?表示匹配0个或1个a
-
但是我们如果要对多个字符进行重复怎么办呢?此时我们就要用到分组,我们可以使用小括号"()"来指定要重复的子表达式,然后对这个子表达式进行重复。
/\d(abc)?/这个正则中(abc)?表示要匹配0个或1个abc,此时这个包含括号的表达式就表示一个分组
捕获组
-
捕获组可以通过从左到右计算其开括号来编号 ,这种分组才会暂存匹配到的串
例如,在表达式
(A)(B(C))中,存在三个这样的组:1 (A) 2 (B(C)) 3 (C) -
"ABC".match(/(A)(B(C))/)

-
"ABC".replace(/(A)(B(C))/, "组1:$1 - 组2:$2 - 组3:$3") // "组1:A - 组2:BC - 组3:C"
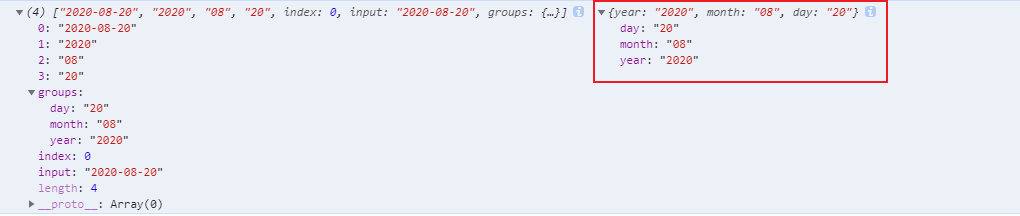
具名捕获组
const reg = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/
const result = reg.exec('2020-08-20')
const groups = result && result.groups
console.log(result, groups)
非捕获组
-
以 ?: 开头的组是纯的非捕获 组,它不捕获文本 。就是说,如果小括号中以?:号开头,那么这个分组就不会捕获文本,当然也不会有组的编号。
-
"ABC".replace(/(?:A)(?:B)(?:C)/, "组1:$1 - 组2:$2 - 组3:$3") // "组1:$1 - 组2:$2 - 组3:$3" -
// 上节里面的前瞻也是非捕获分组 "ABC".replace(/A(?=BC)/, "$1") // "$1BC",因其未捕获,所以$1没有值,就直接按字符串字面值解析。
String和RegExp原型上与正则相关的方法
RegExp
-
RegExp.prototype.test(str)- 检测传入的字符串是否和正则表达式相匹配,一般用test方法只是检测是否有匹配,所以不建议加g
-
RegExp.prototype.exec(str)-
在一个指定字符串中执行一个搜索匹配。返回一个结果数组或
null。 -
var reg1 = /\d(\w)\d/; var str = '$2b3asd4u8989sjf8b4'; var result1 = reg1.exec(str); console.log(result1); // ["2b3", "b", index: 1, input: "$2b3asd4u8989sjf8b4", groups: undefined] // 多个分组 var reg2 = /\d(\w)\d(\w)\d(\w)/; var result2 = reg2.exec(str); console.log(result2); // ["4u8989", "u", "9", "9", index: 7, input: "$2b3asd4u8989sjf8b4", groups: undefined] -
// 如果加了g或y修饰符,我们就可以循环获取匹配到的字符 var reg2= /\d(\w)\d/g; //全局搜索 var str = '$2b3asd4u8989sjf8b4'; var ret; while(ret = reg2.exec(str)) { console.log(`匹配到${ret[0]} ${ret.toString()} 下次查找从${reg2.lastIndex}开始`); } 匹配到2b3 2b3,b 下次查找从4开始 匹配到4u8 4u8,u 下次查找从10开始 匹配到989 989,8 下次查找从13开始 匹配到8b4 8b4,b 下次查找从19开始 -
注意:不要把正则表达式字面量(或者RegExp构造器)放在 while 条件表达式里。由于每次迭代时 lastIndex 的属性都被重置,如果匹配,将会造成一个死循环(一直匹配)。并且要确保使用了'g'标记来进行全局的匹配,否则同样会造成死循环。
-
String
-
String.prototype.search(regexp)-
注意:该方法是强制正则匹配模式,意思是传入的参数不是正则会将其new RegExp(str)转为正则对象。
该方法用于检索字符串中指定的子串,或检索与正则表达式相匹配的子串,该方法只返回第一个匹配结果的index,查找不到返回-1。另外search方法不执行全局匹配,它将忽略标志g,并且总是从字符串的开始进行检索。 -
var str = "123456789.abcde"; console.log( str.search(".") ); // 0 因为new RegExp(".")匹配除回车换行外的任意字符 console.log( str.search("\\.") ); // 9 相当于 new RegExp("\\.") console.log( str.indexOf("\\.") ); // -1 匹配字符 \. 所以不存在
-
-
String.prototype.match(regexp)- 非全局匹配**该方法只执行一次匹配,没有匹配到则返回null,若有匹配返回一个匹配文本相关的数组,返回的数组内容与非全局调用exec方法完全一样。
-
String.prototype.split([separator[, limit]])-
第一个参数是拆分点的字符串或正则,第二个表示返回的拆分元素限制。
-
参数为字符串,不保留分隔符
var myString = "a 123 b 123 c 123 d"; var splits = myString.split("123"); // ["a ", " b ", " c ", " d"] 结果中未保留分隔符 -
参数为正则,假如有分组,结果中会保留分组
var myString = "a 123 b 456 c 789 d"; var splits = myString.split(/\d(\d)\d/); // ["a ", "2", " b ", "5", " c ", "8", " d"] 结果中保留了分组内容
-
-
-
String.protoype.replace(regexp|substr, newSubStr|function)- 一般来说,function有三个参数(如有分组则可能有【3+分组数】个参数),分别是匹配到的字符串、分组内容(若无分组则没有该参数)、index、input(原字符串)
- 内容比较多,详情查看mdn