List集合:
ArrayList:
底层是数组结构,储存有序并且可以重复的对象
package SetTest;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ArrayListTest {
public static void main(String[] args) {
//创建ArrayList的对象
List<Integer> list = new ArrayList<>();
//使用add方法就可以添加
list.add(1);
list.add(2); //是可以重复的
list.add(2);
list.add(3);
list.add(4);
//使用集合工具类Collections
Collections.sort(list); //排序
Collections.reverse(list); //反转
System.out.println(list.toString());
}
}输出:
[1, 2, 2, 3, 4]
[4, 3, 2, 2, 1]
//在ArrayList中重复数据是没问题的
LinkedList:
双向链表式存储,存储有序可重复的对象。LinkedList的实现机制与ArrayList的不同,ArrayList底层是数组实现的,每次插入值的时候先扩容数 组的长度,通过下标获取到该数组的值因此查询元素的效率很高,但是插入和删除需要位移效率很低,所以经 常对元素插入或者删除操作建议不要使用ArrayList,而要采用LinkedList。LinkedList采用双向链表 式存储在增加和删除元素的时候不需要位移,插入和删除效率高。
LinkedList的储存结构:
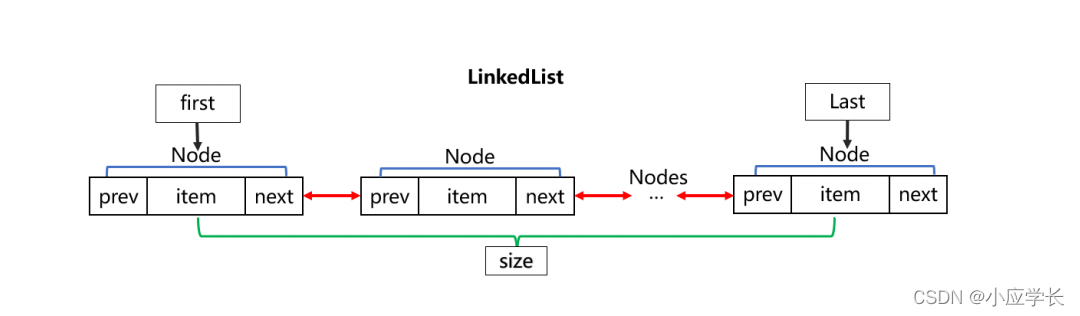
总结:查询多的时候用ArrayList,删除和插入多就用LinkedList
List<Integer> list = new LinkedList<>();//创建LinkedList的对象
其他操作与ArrayList一致
Vector:
Vector和ArrayList集合没有什么太大的区别,底层都是数组实现的,作用也是一致,用来存储大量的有序 的可重复的对象,一般用于大量数据的查询。唯一的区别在于Vector是线程安全的,ArrayList是非线程安全的。
List<Integer> list = new Vector<>();//创建Vector的对象
其他操作与ArrayList一致
Set集合:
HashSet:
是以Hash算法来记录再内存中无序存储的对象
HashSet源码:
public HashSet() {
map = new HashMap<>();
}说明HashSet底层是依赖于HashMap以键值对的形式来存储的无序的集合,通过键来找到值,但是键是 以hash算法来存储的无序集合。
TreeSet:
TreetSet是SortSet接口的实现类,TreeSet可以保证元素处于排序状态再保存。它采用的是红黑树算法数 据结构来存储集合元素。TreeSet支持两种排序:自然排序和定制排序,默认采用自然排序
自然排序:
package SetTest;
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
//treeSet是以红黑树算法将值先排序再保存
Set<Integer> tre = new TreeSet<>();
tre.add(5);
tre.add(3);
tre.add(8);
tre.add(1);
tre.add(4);
for (Integer val:tre){
System.out.println(val);
}
}
}输出:
1
3
4
5
8
定制排序:
Student类:
package TreeSet;
public class Student implements Comparable<Student> {
private String name;
private int age;
private char sex;
public Student(String name, int age, char sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString(){
return "学生的信息是{"+name+age+sex+"}";
}
@Override
public int compareTo(Student obj) {
//这里使用年龄来比较排序
int num = this.age-obj.age;
return num;
}
}测试类:
package TreeSet;
import java.util.Set;
import java.util.TreeSet;
public class test {
public static void main(String[] args) {
//这里生成对象的年龄不按照大小来生成
Student stu1 = new Student("张三",40,'男');
Student stu2 = new Student("李四",32,'男');
Student stu3 = new Student("王五",25,'男');
Set<Student> treeSet = new TreeSet<>();
treeSet.add(stu1);
treeSet.add(stu2);
treeSet.add(stu3);
for (Student stu:treeSet
) {
System.out.println(stu.toString());
}
}
}输出结果:
结果就是按照年龄的大小来进行排序:(这个就是TreeSet的定制排序)
学生的信息是{王五25男}
学生的信息是{李四32男}
学生的信息是{张三40男}
LinkedHashSet:
内部是一个双向链表式结构,所以它插入的值式有序的。因为它插入的时候是使用链表式维护插入的顺 序,所以获取元素的时候应该和插入的顺序一致。但是LinedHashSet性能上低于HashSet,因为除了维护值 以外还需要维护他们的顺序:
package SetTest;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetTest {
public static void main(String[] args) {
//LinkedHashSet 按照插入的顺序读取值
Set<Integer> set = new LinkedHashSet<>();
set.add(40);
set.add(20);
set.add(10);
set.add(30);
for (Integer val:set){
System.out.println(val);
}
}
}输出:(会按照输入的顺序去读值)
40
20
10
30
Map集合:
HashMap:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTest {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("red","红色");
map.put("yellow","黄色");
map.put("green","绿色");
System.out.println(map);
System.out.println(map.get("yellow"));//通过get键去获取值
}
}输出:
{red=红色, green=绿色, yellow=黄色}
黄色 // System.out.println(map.get("yellow"));
HashMap的两种遍历方法:
通过for遍历所有的键,根据键来获取到值(接上部分代码即可)
for (String stu:map.values()
)
System.out.println(stu.toString());{
}输出:
红色
绿色
黄色
用迭代器的方式:(接上部分代码即可)
Set<String> keys = map.keySet();
Iterator<String> it = keys.iterator();
while(it.hasNext()){
String key = it.next();
String stu = map.get(key);
System.out.println(stu.toString());
}输出:
红色
绿色
黄色
注意:如果是存储大量的数据,我们一般是不会用Map去存储。Map一般用于存储小量并且可以无序的 键值对存储的数据。比如登录页面的用户名、密码等等。
LinkedHashMap:
LinkedHashMap是以链表式存储的HashMap,并且是以Hash算法来获取hashcode的值来获取内存中的数 据,存储的顺序和读取的顺序一致:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkHashMap {
public static void main(String[] args) {
//在HashMap里面,添加使用put方法!!
Map<String,String> map = new LinkedHashMap<>();
map.put("yellow","黄色");
map.put("green","绿色");
map.put("red","红色");
System.out.println(map);
}
}输出:
{yellow=黄色, green=绿色, red=红色}
HashTable:
Map<String,String> map = new Hashtable<>();
HashMap和HashTable的作用一样,都是无序的键值对形式存储,HashTable考虑线程安全,HashMap不考 虑线程安全,其他操作一致。
ConcurrentHashMap: 也是和HashMap线程一样,但是它考虑线程安全。HashTable是采用给当前线程加锁实现线程安全, ConcurrentHashMap是采用分段锁机制来实现线程安全:
Map<String,String> map = new ConcurrentHashMap<>();
EnumMap:
专门用来存储枚举的Map集合:
package SetTest;
import java.util.Map;
public class EnumMap {
//枚举
public enum color{
RED,GREEN,YELLOW
}
public static void main(String[] args) {
//枚举map
Map<color,String> map = new java.util.EnumMap<color, String>(color.class);
map.put(color.RED,"红灯");
map.put(color.GREEN,"绿灯");
map.put(color.YELLOW,"黄灯");
System.out.println(color.RED);
String info = map.get(color.RED);
System.out.println("信号信息是:"+info);
}
}集合和数组之间的转换:
import com.sun.corba.se.spi.ior.ObjectKey;
import java.util.Arrays;
import java.util.List;
/**
* 集合和数组之间的转换
*/
public class SetToArr {
public static void main(String[] args) {
String name [] = new String[]{"张三","李四","王五","赵六"};
//将各种数据转换成list集合
List<String> list1 = Arrays.asList(name);
List<String> list2 = Arrays.asList("aa","bb","cc");
List<Integer> list3 = Arrays.asList(100,200,300);
System.out.println("list集合:"+list2);
//list转数组
Object [] newArr = list2.toArray();
String newStr = list2.toString();
System.out.println("数组:"+newStr);
}
}输出:
list集合:[aa, bb, cc]
数组:[aa, bb, cc]
这些就是常用的集合代码举例,大家可以结合上一章的理论知识来看,在这里写的都是一些很简洁的例子,大家多看看就可以理解。
到此这篇关于Java十分钟精通集合的使用与原理下篇的文章就介绍到这了,更多相关Java 集合内容请搜索好代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好代码网!