一、为什么需要超时控制
在日常开发中,对于RPC、HTTP调用设置超时时间是非常重要的。那为什么需要超时控制呢?我们可以从用户、系统两个角度进行考虑;
- 用户角度:在这个快节奏的时代,如果一个接口耗时太长,用户可能已经离开页面了。这种请求下,后续的计算任务就没用了。比如说,最近的AIGC,我们有个需求需要用到微软的ChatGPT,这类接口有个特点,耗时不受控制,可能30s,可能1min,我们和产品讨论以后,这个接口最后的超时时间设置为9s。(说实在,有点短,很多超时的情况)
- 系统角度:因为HTTP、RPC请求均会占用资源,比如链接数、计算资源等等,尽快返回,可能防止资源被耗尽的请求;
现在,我们知道要设置超时时间了,那就有个问题,超时时间设置为多少呢?设置太小,可能会出现大面积超时的情况,不符合业务需求。设置太长,可能会有以上两个缺点。
二、超时时间设置为多少
超时时间的设置可以从这四个角度考虑:
- 问产品;产品从业务、用户的角度,行为考虑,这个页面他们能够接受的时间是多少。
- 看历史数据;我们可以看这个接口历史数据的99线,也就是99%的接口耗时是多少。
- 压测;如果这是个新接口,没有历史数据可查,那么我们可以考虑进行压测,观察99%接口耗时是多少;
- 计算代码逻辑;通过巴拉代码,看有多少次MySQL、redis查找与插入;
上面四个方法,只要有一个凑效就行,但是,我们要秉承数据来源要有依据这条原则,优先考虑历史数据、压测,其次结合业务需求,决定是否需要优化代码等等。
三、超时控制的种类
在微服务框架中,我们一个请求可能需要经历多个服务,那么在生产环境下,咱们应该得两手抓:
- 链路超时:也就是在服务进入gate-api的时候,应该设置一个链路时间。(我们服务设置的是10s)
- 服务时间:每个微服务请求其他服务的超时时间。(我们设置的是3s)
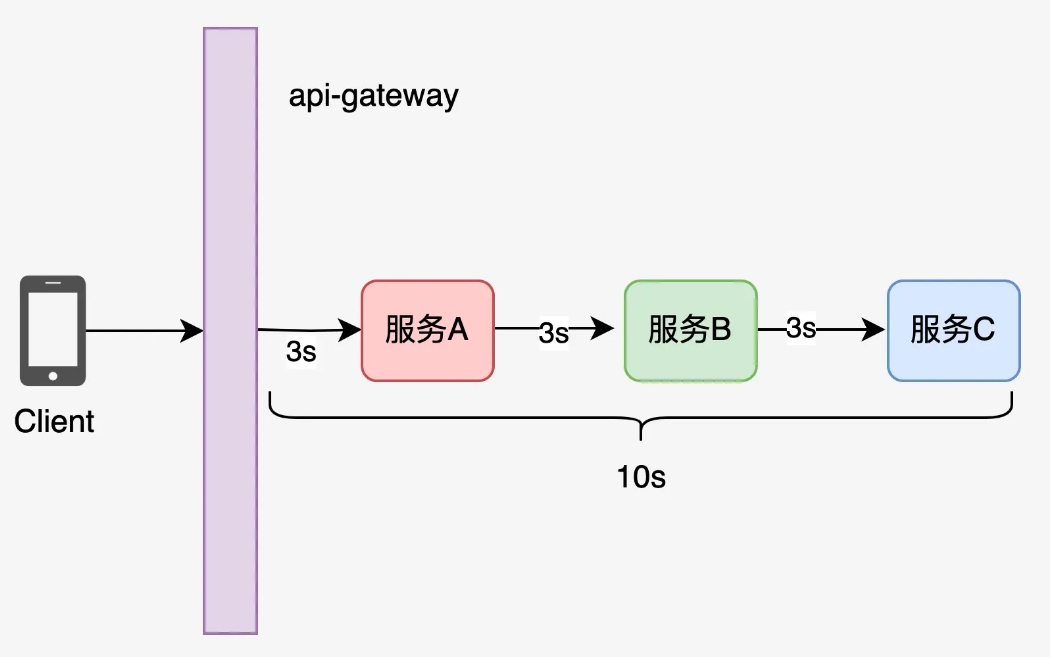
【注:我们公司大概是这样的】
上面,服务时间的控制里头,有包含两方面,客户端超时控制与服务端超时控制,我们通过一个例子来表述这两者之间的差异。如果A服务请求B服务,这个请求设置的超时时间为3s,但是B服务处理数据的需要话费两分钟,那么:
- 对于A客户端,rpc框架大部分都设置了客户端超时时间,3s就会返回了。
- 对于B服务端,当客户端3s超时了,那是否还需要执行两分钟呢?这个一般都会继续执行了(我们公司就会执行),如果你在代码里头有明确的校验超时时间,也能做到只执行3s的。
接下来,我们来看几个例子。
四、Golang超时控制实操
案例一
func hardWork(job interface{}) error {
time.Sleep(time.Minute)
return nil
}
func requestWorkV1(ctx context.Context, job interface{}) error {
ctx, cancel := context.WithTimeout(ctx, time.Second*2)
defer cancel()
// 仅需要改这里即可
// done := make(chan error, 1)
done := make(chan error)
// done 退出以后,没有接受者,会导致协程阻塞
go func() {
done <- hardWork(job)
}()
select {
case err := <-done:
return err
case <-ctx.Done(): // 这一部分提前退出
return ctx.Err()
}
}
// 可以做到超时控制,但是会出现协程泄露的情况
func TestV1(t *testing.T) {
const total = 1000
var wg sync.WaitGroup
wg.Add(total)
now := time.Now()
for i := 0; i < total; i++ {
go func() {
defer wg.Done()
requestWorkV1(context.Background(), "any")
}()
}
wg.Wait()
fmt.Println("elapsed:", time.Since(now)) // 2秒后打印这条语句,说明协程只执行了两秒
time.Sleep(time.Minute * 2)
fmt.Println("number of goroutines:", runtime.NumGoroutine()) // number of goroutines: 1002
}
执行上述代码:我们会发现协程执行2秒就退出了 【满足我们超时控制需求】 ,但是第2个打印语句显示协程泄漏了,当前有1002个协程;
原因:select中的协程提前退出,从而导致无缓存chan没有接受者,从而导致协程泄漏。只需要将无缓存chan改为有缓存chan即可。
五、GRPC中如何做超时控制
接着,我们在看看在GRPC中,我们如何做超时控制。
首先,我们看下这个小Demo的目录结构:
.
├── client_test.go
├── proto
│ ├── hello.pb.go
│ ├── hello.proto
│ └── hello_grpc.pb.go
└── server_test.go
定义接口IDL文件
syntax = "proto3";
package helloworld;
option go_package = ".";
service Greeter {
rpc SayHello (HelloRequest) returns (HelloReply);
}
message HelloRequest {
string name = 1;
}
message HelloReply {
string message = 1;
}
执行protoc工具
hello git:(master) ✗ protoc -I proto/ proto/hello.proto --go_out=./proto --go-grpc_out=./proto
写client代码
const (
address = "localhost:50051"
defaultName = "world"
)
func TestClient(t *testing.T) {
conn, err := grpc.Dial(address, grpc.WithInsecure())
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
c := pb.NewGreeterClient(conn)
name := defaultName
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
r, err := c.SayHello(ctx, &pb.HelloRequest{Name: name})
if err != nil {
log.Fatalf("could not greet: %v", err)
}
log.Printf("Greeting: %s", r.Message)
}
在客户端代码中,我们只需要设置ctx即可。grpc客户端框架就会帮我们监控ctx,只要超时了就会返回。
写server代码
func (s *server) SayHello(ctx context.Context, request *pb.HelloRequest) (*pb.HelloReply, error) {
logrus.Info("request in")
time.Sleep(5 * time.Second)
//select {
//case <-ctx.Done():
// fmt.Println("time out Done")
//}
logrus.Info("requst out")
if ctx.Err() == context.DeadlineExceeded {
log.Printf("RPC has reached deadline exceeded state: %s", ctx.Err())
return nil, ctx.Err()
}
return &pb.HelloReply{Message: "Hello, " + request.Name}, nil
}
func TestServer(t *testing.T) {
lis, err := net.Listen("tcp", ":50051")
if err != nil {
log.Fatalf("Failed to listen: %v", err)
}
s := grpc.NewServer()
pb.RegisterGreeterServer(s, &server{})
if err := s.Serve(lis); err != nil {
log.Fatalf("Failed to serve: %v", err)
}
}
服务端,grpc框架就没有替我们监控了,需要我们自己写逻辑,上述代码可以通过注释不同部分,验证以下几点:
- grpc框架没有替我们监控
ctx,需要我们自己监控; - 通过
select监控ctx; - 通过
context.DeadlineExceeded来监控ctx,从而提前返回;
六、GRPC框架如何监控超时的呢
代码在grpc/stream.go文件:
func newClientStreamWithParams(ctx context.Context, desc *StreamDesc, cc *ClientConn, method string, mc serviceconfig.MethodConfig, onCommit, doneFunc func(), opts ...CallOption) (_ iresolver.ClientStream, err error) {
// .....
if desc != unaryStreamDesc {
// Listen on cc and stream contexts to cleanup when the user closes the
// ClientConn or cancels the stream context. In all other cases, an error
// should already be injected into the recv buffer by the transport, which
// the client will eventually receive, and then we will cancel the stream's
// context in clientStream.finish.
go func() {
select {
case <-cc.ctx.Done():
cs.finish(ErrClientConnClosing)
case <-ctx.Done():
cs.finish(toRPCErr(ctx.Err()))
}
}()
}
}
可以看到,在newClientStreamWithParams中,GRPC替我们起了一个协程,监控ctx.Done。
以上就是一文带你搞懂go中的请求超时控制的详细内容,更多关于go请求超时控制的资料请关注好代码网其它相关文章!