前言:这篇文章是为了初次接触Dedecms采集功能的朋友所写的。所选取的目标站点为文章内容页面不含有分页的Dedecms官方网站的dreameaver栏目文章,通过图文并茂的形式,详细地介绍了如何创建一个基本的采集规则。本文共分为三节:第一节,主要是介绍如何进入采集界面和新增采集节点中的第一步:设置基本信息及网址索引页规则;第二节,主要是介绍新增采集节点中的第二步:设置字段获取规则;第三节,主要是介绍如何采集指定节点和如何导出采集内容。下面进入第一节。
1.1进入采集节点管理界面
如(图1)所示,在后台管理界面的主菜单中单击"采集",然后单击"采集节点管理",即可进入采集节点管理界面,如(图2)所示。
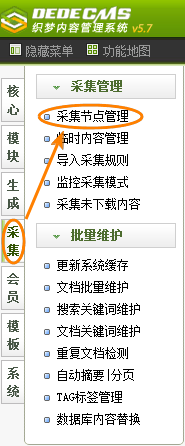
图1-后台管理界面

图2-采集节点管理界面
1.2. 增加新节点
在采集节点管理界面中,单击左下角的"增加新节点"或者右上角的"添加新节点"(如图2),都可进入"选择内容模型"界面,如(图3)所示,

图3-选择内容模型界面
在"选择内容模型"界面的下拉列表框中,有"普通文章"和"图片集"可供选择。根据被采集页面的类型,选择相应的内容模型。本文这里选择"普通文章",单击确定后,便可进入"新增采集节点:第一步设置基本信息及网址索引页规则"界面,如(图4)所示,

图4-新增采集节点:第一步设置基本信息及网址索引页规则
1.2.1 设置节点基本信息
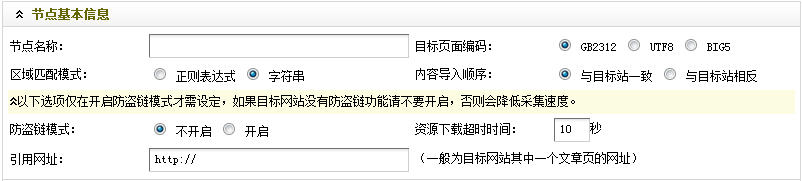
图5-节点基本信息
如(图5)所示,
节点名称:给新建立的节点起一个名字,这里填上"采集测试(一)";
目标页面编码:设定被采集目标页的编码格式,有GB2312、UTF8和BIG5三种。可通过在被采集目标页面上,单击右键后选择"查看源文件"来获取。
操作步骤:
(a)打开被采集的目标页:http://www.dedecms.com/knowledge/web-based/dreamweaver/;
(b)单击右键后选择"查看源文件",找到"charset", 如(图6)所示,

图6-查看源文件
其等号后面的代码就是所需的"编码格式",这里是"gb2312"。
"区域匹配模式":设定如何匹配所需采集的内容部分,可采用字符串或者正则表达式。系统默认的模式是字符串。如果比较了解正则表达式的朋友,可以在这里选择正则表达式的模式。
"内容导入顺序":指定文章列表导入时候的顺序,可以选择"与目标站一致"或"与目标站相反"。
"防盗链模式":针对被采集的目标站点有无刷新限制。一开始很难判断出来,需要测试后才能知道。如果有的话,这里需要设置一下"资源下载超时时间"。
"引用网址":填入任何一个即将被采集的文章内容页面的网址。
具体操作步骤:
(a)在已打开的文章列表页中,单击第一篇文章的
标题"在Dreamweaver中为插入的Flash添加透明",以打开文章内容页面,如(图7)所示,
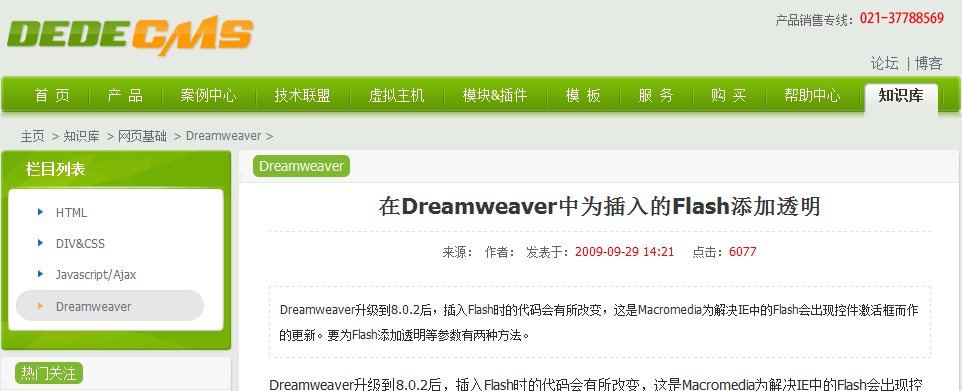
图7-文章内容页面
(b)此时在浏览器的URL地址栏中显示的网址,即为需要填写在"引用网址"处的网址,如(图8)所示,

图8-浏览器的URL地址栏
到这里,"节点基本信息"就设置完成了。最后结果,如(图9)所示,
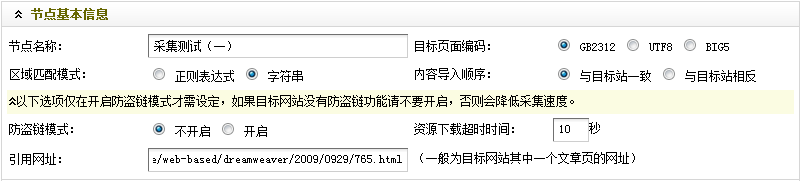
图9-设置后的节点基本信息
检查无误后,进入下一步设置。
1.2.2 设置列表网址获取规则
如(图10)所示,

图10-列表网址获取规则
这里是设置被采集的文章列表页的匹配规则。如果被采集的文章列表页有一定的规律,可选择"批量生成列表网址";如果被采集的文章列表页完全没有规律可循,那么可选择"手工指定列表网址";如果被采集的站点提供了RSS,则可以选择"从RSS中获取"。对于特殊情况,例如:部分列表页有规律,而其余的又没有规律,则可在"匹配网址"中填上有规律的部分,然后把没有规律的部分填写在"手动指定网址"。
具体操作步骤:
(a)首先,回到已打开的文章列表页,找到浏览器的URL地址栏中显示的网址(图8)和页面底部的换页部分。如(图11)所示,

图11-换页
(b)单击"2",打开文章列表页的第二页,此时浏览器的URL地址栏中所显示的网址和页面底部的换页部分,如(图12)和(图13)所示,

图12-第二页的网址

图13-第二页的换页部分
(c)在已打开的文章列表页的第二页上面,单击(1),打开文章列表页的首页,这时页面底部的换页部分与图11相同,而浏览器的URL地址栏中所显示的网址与之前图8并不相同,如(图14)所示,

图14-第一页的网址
(d)由(b)和(c)推知,此处被采集的文章列表页的网址所遵循规律为:
http://www.dedecms.com/knowledge/web-based/dreamweaver/list_47_(*).html。稳妥起见,请自行测试更多列表页。确定规律后,在"匹配网址"中,填入文章列表页所遵循的规律。
(e)最后,指定需要采集的页码或者规律数字,并设定其递增规律。
到这里,"列表网址获取规则"部分就设置结束了。最后结果,如(图15)所示,
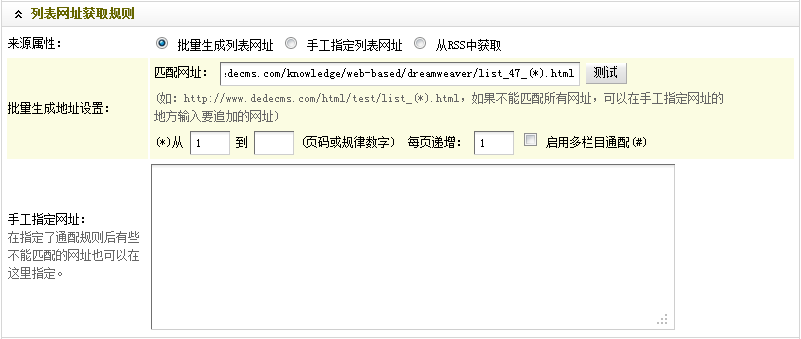
图15-设置后的列表网址获取规则
确定正确后,进入下一步设置。
1.2.3设置文章网址匹配规则
如(图16)所示,
图16-文章网址匹配规则
这里是设置被采集文章列表页的匹配规则。
具体操作步骤:
(a)对于"区域开始的HTML",可通过在打开的文章列表首页上,单击右键后选择"查看源文件"。在源文件中,找到第一篇文章的标题"在Dreamweaver中为插入的Flash添加透明",如(图17)所示,

图17-查看源文件中,第一篇文章的标题
通过观察,不难看出"<div class="arc_list">"为整个文章列表的开始部分。因此,在"区域开始的HTML"中,填入"<div class="arc_list">"。
(b)在源文件中,找到最后一篇文章标题"通过Dreamweaver设计网页时组织CSS的建议",如(图18)所示,

图18-查看源文件中,最后一篇文章的标题
结合文章列表的开始部分并通过观察可知,第一个"</div>"为整个文章列表的结束部分。因此,在"区域结束的HTML"中,应填入"</div>"。
"如果链接中含有图片":设置对链接中含有图片的处理方式,有不处理和采集为缩略图可选。可根据实际需要选择。
"对区域网址进行再次筛选":可以使用正则表达式对区域网站进行再次筛选,这是针对一些需要被保留或者需要滤掉的内容,尤其是混编的列表页面,通过使用"必须包含"或者"不能包含"过滤掉所希望获取或者不希望获取的文章内容页面的网址。
具体操作步骤:
回到正在打开的文章列表首页的源文件,通过观察可知,每一个文章内容页面地址的扩展名均为.html。因此,可在"必须包含"中,填入".html"。
到这里,"文章网址匹配规则"就设置结束了。最后结果, 如(图19)所示,
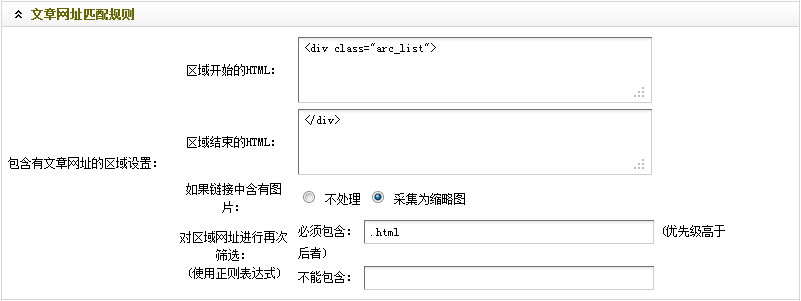
图19-设置后的文章网址匹配规则
通过1.2.1小节、1.2.2小节和1.2.3小节,新增采集节点的第一步就已经设置完成了。设置后的结果,如(图20)所示,
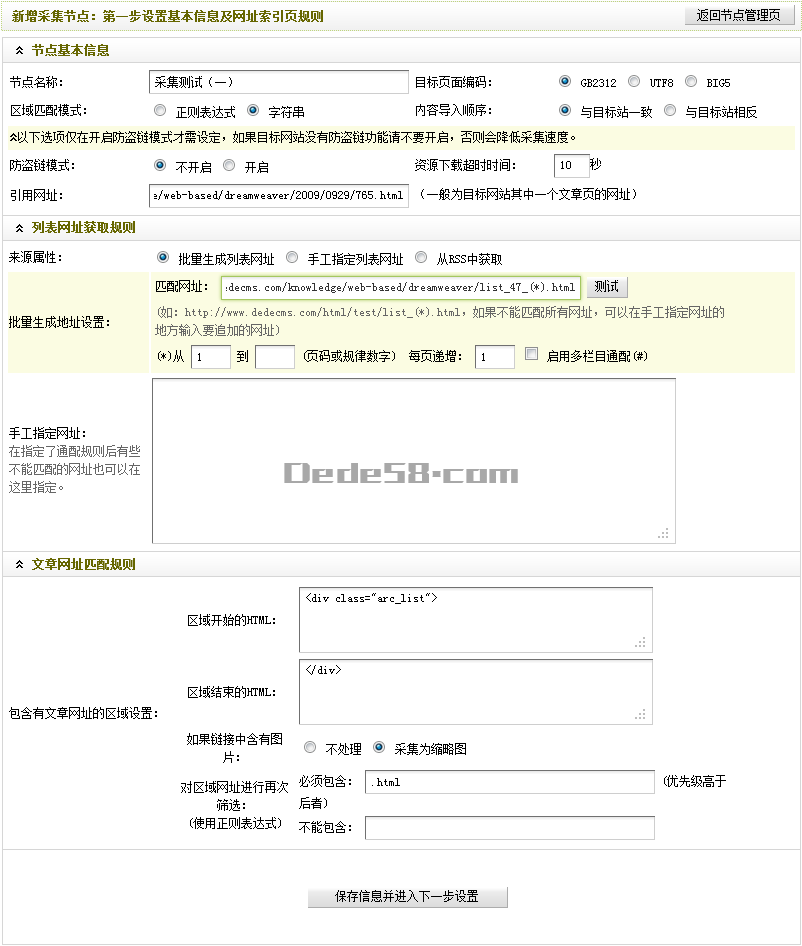
图20-设置后的新增采集节点:第一步设置基本信息及网址索引页规则
全部完成并检查无误后,单击"保存信息并进入下一步设置"。如果之前设置正确,单击后,将会进入"新增采集节点:测试基本信息及网址索引页规则设置的网址获取规则测试"页面并看到相应的文章列表地址。如(图21)所示,

图21-网址获取规则测试
确定正确无误后,单击"保存信息并进入下一步设置"。否则,请单击"返回上一步进行修改"。
本文Dedecms织梦后台模板采集功能的如何使用方法详解到此结束。我是说阿里巴巴发现了金矿,那我们绝对不自我去挖,我们期望别人去挖,他挖了金矿给我一块就能够了。小编再次感谢大家对我们的支持!